|
|
kappa系数是什么
Kappa系数是一个用于一致性检验的指标,也可以用于衡量分类的效果。因为对于分类问题,所谓一致性就是模型预测结果和实际分类结果是否一致。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。
基于混淆矩阵的kappa系数计算公式如下:
kappa = \frac{p_o-p_e}{1-p_e}
其中:
p_o = \frac {对角线元素之和}{整个矩阵元素之和} ,其实就是acc。
p_e = \frac{\sum_{i}{第i行元素之和 * 第i列元素之和}}{(\sum{矩阵所有元素})^2} ,即所有类别分别对应的“实际与预测数量的乘积”,之总和,除以“样本总数的平方”。
为什么要使用kappa
分类问题中,最常见的评价指标是acc,它能够直接反映分正确的比例,同时计算非常简单。但是实际的分类问题种,各个类别的样本数量往往不太平衡。在这种不平衡数据集上如不加以调整,模型很容易偏向大类别而放弃小类别(eg: 正负样本比例1:9,直接全部预测为负,acc也有90%。但正样本就完全被“抛弃”了)。此时整体acc挺高,但是部分类别完全不能被召回。
这时需要一种能够惩罚模型的“偏向性”的指标来代替acc。而根据kappa的计算公式,越不平衡的混淆矩阵, p_e 越高,kappa值就越低,正好能够给“偏向性”强的模型打低分。
kappa系数计算示例
混淆矩阵:
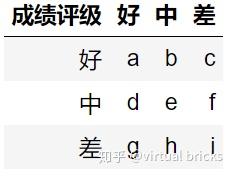
学生实际的成绩评级和预测的成绩评级
p_o = \frac{a+e+i}{a+b+c+d+e+f+g+h+i}
p_e = \frac{(a+d+g)\times(a+b+c) + (b+e+h)\times(d+e+f) + (c+f+i)\times(g+h+i)}{(a+b+c+d+e+f+g+h+i)^2}
将 p_o 和 p_e代入 kappa = \frac{p_o-p_e}{1-p_e} 即可。
编程计算kappa值
import numpy as np
# 没有对输入的合法性进行校验
# 使用时需要注意
def kappa(confusion_matrix):
"""计算kappa值系数"""
pe_rows = np.sum(confusion_matrix, axis=0)
pe_cols = np.sum(confusion_matrix, axis=1)
sum_total = sum(pe_cols)
pe = np.dot(pe_rows, pe_cols) / float(sum_total ** 2)
po = np.trace(confusion_matrix) / float(sum_total)
return (po - pe) / (1 - pe) 使用无偏向和有偏向的混淆矩阵分别测试
# 无偏向的混淆矩阵
balance_matrix = np.array(
[
[2, 1, 1],
[1, 2, 1],
[1, 1, 2]
]
)
# 有偏向的混淆矩阵
unbalance_matrix = np.array(
[
[0, 0, 3],
[0, 0, 3],
[0, 0, 6]
]
)
kappa_balance = kappa(balance_matrix)
print("kappa for balance matrix: %s" % kappa_balance)
kappa_unbalance = kappa(unbalance_matrix)
print("kappa for unbalance matrix: %s" % kappa_unbalance)
kappa for balance matrix: 0.25
kappa for unbalance matrix: 0.0结论: 上面两个混淆矩阵的acc一样,但是kappa值不同,偏向性强的kappa值低。
from sklearn.metrics import cohen_kappa_score
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
kappa_value = cohen_kappa_score(y_true, y_pred)
print("kappa值为 %f" % kappa_value)
kappa值为 0.428571
import tensorflow as tf
y_t = tf.constant(y_true)
y_p = tf.constant(y_pred)
kappa, update = tf.contrib.metrics.cohen_kappa(y_t, y_p, 3)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
print(kappa.eval(), update.eval())
print(kappa.eval(), update.eval())
0.0 0.42857142857142855
0.42857142857142855 0.42857142857142855注意 如上例结果,tensorflow一开始将kappa初始化为0 返回值中“kappa”是运行计算图之前的kappa值,“update”才是运行了计算图后的kappa值。 不可像调用sklearn那样直接把返回的“kappa”参数作为kappa值。 |
|



 发表于 2022-9-20 18:28:42
发表于 2022-9-20 18:28:42