|
|
赛题任务:
基于Caltech数据集的图像分类,Caltech101包含102个类,每种类别大约40到800个图像,训练集总计7999图像。本次试题需要图片为输入,通过课程学习的分类方法(支持向量机、深度神经网络、卷积神经网络等)从中识别该图像属于哪一个类别。
数据说明
images下存储所有的训练+测试图像,trian.txt中存储用于训练图像路径和对应标注,图片路径+\t+标签,test.txt中存储测试图像。
限制:
只能用paddle框架和在astudio上运行代码
提交答案
考试提交,需要提交模型代码项目版本和结果文件。结果文件为TXT文件格式,命名为result.txt,文件内的字段需要按照指定格式写入。 结果文件要求: 1,每一行为: 图像名\t标签 101_0073.jpg\t13 2.输出结果应检查是否为1145行数据,否则成绩无效。 3.输出结果文件命名为result.txt,一行一个数据
基本思路:
为了方便使用各种技巧,我使用了paddlex框架,这是由paddle写出的封装性强、使用便捷的框架,并且对数据集划分训练集和验证集,使用有知识蒸馏的技巧的resnet101模型。训练前我对训练集使用了数据增强,包括随机翻转、mixup、正则化等,训练时采用了标签平滑、学习率衰减等策略,模型准确率达到97%,我再将全部的数据都放进模型训练,对测试集进行测试,提交后准确率达到98%。
!unzip /home/aistudio/data/data146107/dataset.zip -d /home/aistudio/data
# 导入需要的包
import paddle
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
import pickle
from paddle.vision.transforms import ToTensor
import paddle.nn.functional as F
print("本教程基于Paddle的版本号为:"+paddle.__version__)
from sklearn.utils import shuffle
# 划分数据集,生成验证集
total_list = []
f = open('/home/aistudio/data/dataset/train.txt', 'r', encoding='utf-8')
# total_len = len(f.readlines())
# print(f.readlines())
total_list = f.readlines()
f.close()
total_list = shuffle(total_list, random_state = 100)
train_len = int(0.85 * 7999)
train_list = total_list[:train_len]
val_list = total_list[train_len:]
f1 = open('/home/aistudio/data/dataset/train1.txt', 'w', encoding='utf-8')
f2 = open('/home/aistudio/data/dataset/val.txt', 'w', encoding='utf-8')
for line in train_list:
f1.write(line)
for line in val_list:
f2.write(line)
f1.close()
f2.close()
f3 = open('/home/aistudio/data/dataset/label.txt', 'w', encoding='utf-8')
f = open('/home/aistudio/data/dataset/class.txt', 'r', encoding='utf-8')
for line in f.readlines():
label_name, label_id = line.strip().split('\t')
f3.write(label_name+'\n')
f3.close()
!pip install paddlex
from paddlex import transforms as T
train_transforms = T.Compose([
# T.RandomHorizontalFlip(),
# T.RandomVerticalFlip(),
# T.MixupImage(alpha=1.5, beta=1.5, mixup_epoch= -1),
# T.RandomBlur(prob=0.1),
# T.RandomDistort(),
T.Normalize(),
T.Resize(224)
])
eval_transforms = T.Compose([
T.Normalize(),
T.Resize(224)
])
import paddlex as pdx
train_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/dataset/images/',
file_list='/home/aistudio/data/dataset/train1.txt',
label_list='/home/aistudio/data/dataset/label.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/dataset/images/',
file_list='/home/aistudio/data/dataset/val.txt',
label_list='/home/aistudio/data/dataset/label.txt',
transforms=eval_transforms)
total_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/dataset/images/',
file_list='/home/aistudio/data/dataset/train.txt',
label_list='/home/aistudio/data/dataset/label.txt',
transforms=train_transforms,
shuffle=True)
num_classes = len(train_dataset.labels)
# model = pdx.cls.ResNet101_vd_ssld(num_classes=num_classes)
model = pdx.load_model('output/resnet101_ssld1//best_model') # 导入效果最好的模型
model.train(num_epochs=20,
train_dataset=train_dataset,
train_batch_size=64,
eval_dataset=eval_dataset,
lr_decay_epochs=[10, 15, 20],
save_dir='output/resnet101_ssld2',
label_smoothing = True,
# optimizer=paddle.optimizer.Adam,
use_vdl=True)
model = pdx.load_model('output/resnet101_ssld1//best_model') # 导入效果最好的模型
model.evaluate(eval_dataset, batch_size=1, return_details=True) # 验证集结果
# 这里可以考虑把所有数据都进行训练
model.train(num_epochs=15,
train_dataset=total_dataset,
train_batch_size=64,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/resnet101_ssld1',
label_smoothing = True,
use_vdl=True)
# 预测结果
model = pdx.load_model('output/resnet101_ssld2/best_model') # 导入效果最好的模型
test_path = "/home/aistudio/data/dataset/images/"
test_files = []
f = open('/home/aistudio/data/dataset/test.txt', 'r', encoding='utf-8')
for line in f.readlines():
test_files.append(test_path+line.strip())
f.close()
result = model.predict(img_file = test_files, transforms = eval_transforms)
print("Predict Result:\n", result)
f = open('/home/aistudio/result.txt', 'w', encoding='utf-8')
k = 0
for d in result:
img_name = test_files[k].split('/')[-1]
f.write(img_name + '\t' + str(d[0]['category_id']) + '\n')
k += 1
f.close()
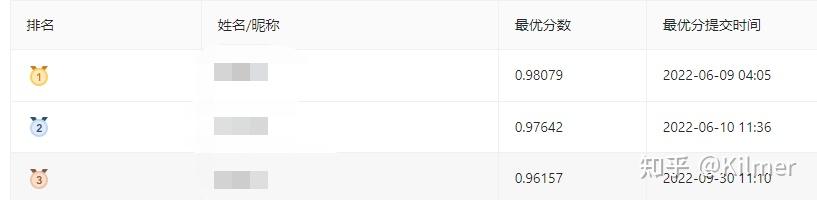
最终分数0.98079分,排名第一
 |
|



 发表于 2022-12-31 17:34:45
发表于 2022-12-31 17:34:45