|
|
PIT
Pit方法不同于多类回归问题或者deep clustering。它是直接优化最小的分离损失(pit & upit是优化mse损失,如果把mse损失换成SNR会有什么结果呢?类似TasNet)
CASA计算听觉场景分析:机器将声音信号转化为有意义的信息的过程
分类网络通常需要混合物和其并行的目标源。优化网络以预测通常属于每个时频仓的,属于目标类别的源。
类似这样(mix<—>[target_spk1, target_spk2])
为什么大部分人都去做音乐或者背景噪声的分离,因为语音的特征相较于背景或音乐的特征更加复杂。音乐/噪声的音色比较固定。
DPCL方法对于two speaker和three speaker分离效果都是比较好的,但是DPCL方法存在一个近似假设,假设某一个tf-bins只属于一个speaker,这毫无疑问是不正确的。此外,该方法不能够与其他的方法结合(这个也是为什么PIT方法在后面语音分离任务上使用的更加广泛)。
先前的一些语音分离任务将该任务当做多类回归问题,分割问题,聚类问题。

这个说的意思就是我们在训练的时候仅考虑幅度谱,在测试的时候我们才考虑相位信息。

这一部分我比较存疑,因为在DPCL的文章里其实在inference也是变相的通过深度学习网络来估计mask。
首先文章中提出了一个损失函数使用的是IRM
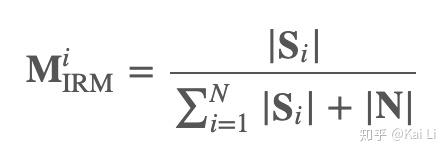
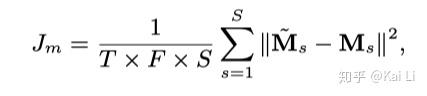
但是这样就会出现一个问题。当存在slience区域时,mask的分子和分母都为零不方便计算。
因此,pit文章中介绍了另一种改进。直接将预测的audio与真实的audio之间计算mse损失。这就可以避免分子分母为零无法计算的情况。

PIT:就是他的训练准则。
Segment-based decision marking:在inference用来标记每一个meta-frame的位置。

这里说的意思应该是reference source是以集合形式给出,而不是一个有序列表。这是也是pit的训练准则,找到所有排列组合中最小的loss。

meta-frame: 在文章中说的意思是连续的N帧。

这个内容我个人想法是和下面的图类似。如果一个utterance被分为五个meta-frame,而他们通过pit方法输出的结果并不一定按照他们输入的顺序输出。
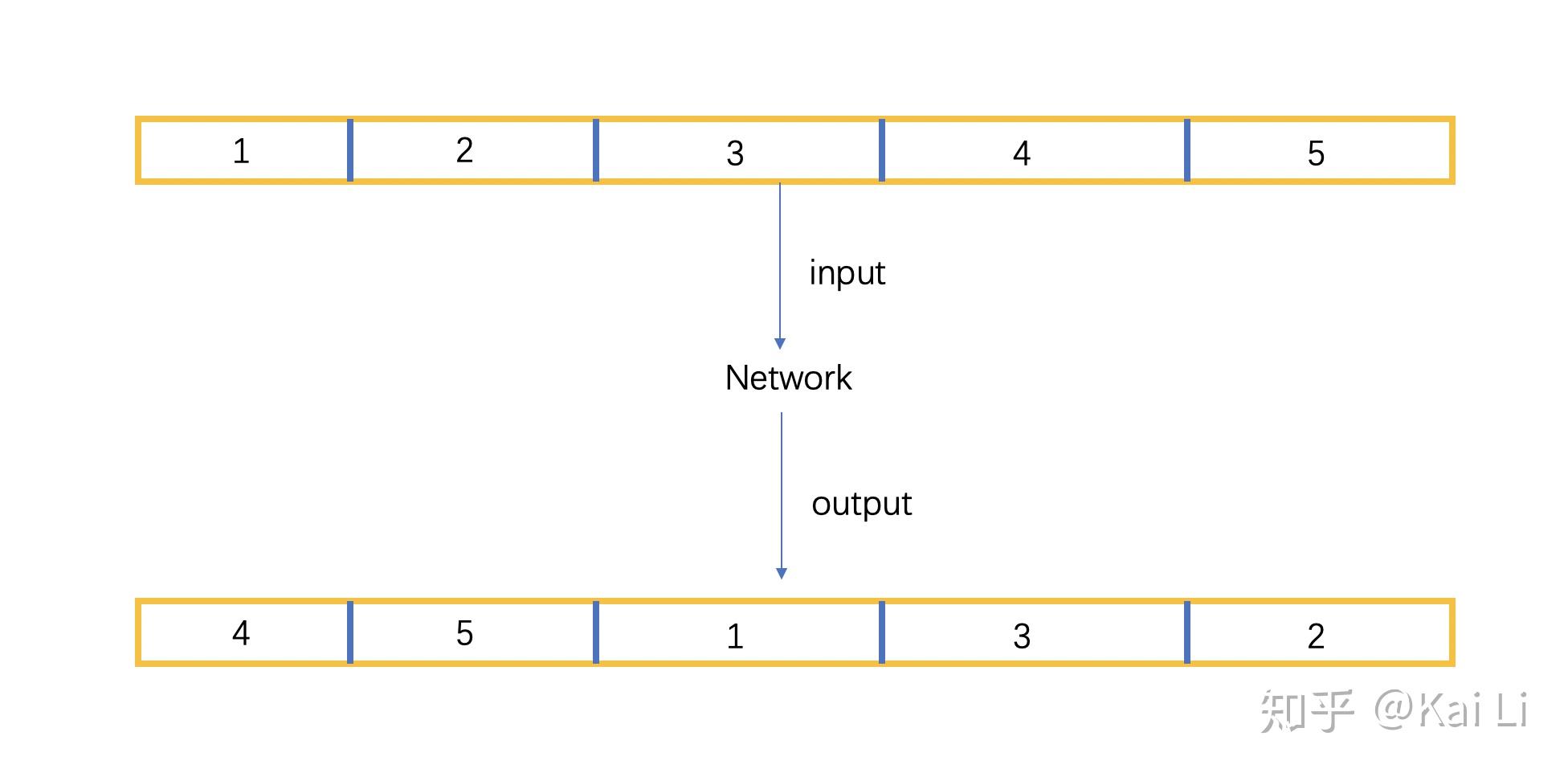
于是就设计一种speakertracing algorithm方法来应用在network的输出部分。本身论文并没有提出speaker tracking的算法,直接和target比算的oracle结果。
<hr/>uPIT
在该篇文章说了DPCL的另一个问题,也是DPCL核心问题:就是DPCL的目标函数是mix和target的embedding之间的差距,而我们真正想要是不同utterances之间的差距。
其实uPIT的方法就是使用了LSTM将原来PIT的meta-frames改为整个utterance。 本篇文章还提出了IAM(Ideal Amplitude Mask), IPSM(Ideal Phase Sensitive Mask), INPSM(Ideal Nonnegative PSM).
参考文献:
- Hershey J R, Chen Z, Le Roux J, et al. Deep clustering: Discriminative embeddings for segmentation and separation[C]//2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016: 31-35.
- Yu D, Kolbæk M, Tan Z H, et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017: 241-245.
- Yu D, Kolbæk M, Tan Z H, et al. Permutation invariant training of deep models for speaker-independent multi-talker speech separation[C]//2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017: 241-245
|
|



 发表于 2023-1-8 15:29:57
发表于 2023-1-8 15:29:57