|
|
今天介绍论文《Hindsight Experience Replay》。
本文针对稀疏奖励问题提出了一种十分有效的经验回放技术HER,HER以UVFA为基础,其思想比较简单,全文没有十分高深的理论推导和分析,但是实验证明HER确实是一种非常有效的方法,并且对后续的很多工作有很大的借鉴意义,例如分层强化学习中的HAC,另外这篇论文叙述得很清楚,仿真实验也很grounded,是一篇很值得阅读的论文,推荐指数 ★★★★★。 本文针对的是一种特殊场景:环境中只存在即为稀疏的二元奖励,该奖励用于表示任务是否完成,即只有任务完成的时候智能体会得到一个奖励。在这种场景下,策略的学习十分困难。为了辅助智能体快速找到策略,一种常用的方法是 reward shaping,即根据对环境的先验信息人为设计奖励,但这种方法需要我们具备对特定场景的知识,并根据这些知识精心设计奖励,另外,这些reward所表示的含义有可能与原本我们的目标是相悖的,因此并不适用于某些我们不知道合理行为是何种行为的场景中,因此研究如何从 unshaped reward 中学习策略 具有十分重要的意义,例如反映任务是否成功完成的二元奖励,这就是本文的出发点。
为了引出本文的核心思想,论文一开始举了一个人类打篮球的例子,当我们在学习如何打篮球的时候,不小心把球打在了篮网的右边,由于人类具备从失败案例中学习的能力,我们可以分析出发力的时候稍微靠左一点,就有可能投入篮筐,但是在强化学习中,智能体只能从这样一个transition中得知该动作无法成功,除此之外不能学习到其他知识。那么我们是否能让智能体像人类一样在任务没有完成的情况下也学习到足够多的技能呢?
本文提出了 Hindsight Experience Replay (HER)方法,该方法可以与任意 off-policy 算法结合,适用于有多个 目标(goals) 需要实现的场景。HER不仅可以提升训练的样本效率,更重要的是,它可以在奖励是二元且稀疏的情况下学习到好的策略。HER以UVFA中所提出的同时基于状态和目标的值函数为基础,其背后的思想是:在回放每个episode时,用一个新的目标替代原本智能体需要完成的目标,这个新的目标是本episode中实现过的目标,有点类似事后诸葛亮的感觉。
Hindsight Experience Replay
Multi-goal RL
本文考虑训练智能体实现多个不同的目标(goals),因此本文借鉴了UVFA的方法,即策略函数与值函数的输入不仅包含状态 s\in\mathcal{S},还包含目标 g\in\mathcal{G}。另外,经过实验证实,训练智能体实现多个目标比只实现一个目标要学得更快,因此HER同样适用于只有一个目标需要实现的场景。
假定每个目标 g\in\mathcal{G} 对应着一个预测:f_g:\mathcal{S}\rightarrow \{0,1\},智能体的目标是努力去达到某个状态使得 f_g(s)=1。当我们明确的知道我们希望达到什么样的目标时,有 \mathcal{S}=\mathcal{G} 以及 f_g(s)=[s=g]。而当我们只是需要达到某些特征的状态时,例如假设有 \mathcal{S}=\mathbb{R}^2,目标是达到任意给定 x 坐标值的状态,此时我们有 \mathcal{G}=\mathbb{R} 以及 f_g((x,y))=[x=g]。
另外,我们还假设给定任意状态 s,均可以找到该状态所能够实现的目标 g。即存在映射 m: \mathcal{S} \rightarrow \mathcal{G} \text { s.t. } \forall_{s \in \mathcal{S}} f_{m(s)}(s)=1。在上一段描述的第一个例子中,m 就是一个恒等式,即 m(s)=g,而在第二个例子中,m((x,y))=x。
上述问题可以通过任意 off-policy 算法求解,此时奖励设定为,r_g(s,a)=-[f_g(s)=0]。但是这种方式通常不能获得很好的性能,因为奖励函数过于稀疏且没有提供有效的信息。为此,本文提出Hindsight Experience Replay技术来解决该问题。
HER算法
HER背后的思想十分简单:经过了一个episode s_0,s_1,...,s_T 之后,我们将每个transition s_t\rightarrow s_{t+1} 存储起来,每个experience里的目标不仅包含初始设定的目标,还包含一些重新设定的目标。之所以可以这么做的原因是目标只会影响智能体的动作,但是并不会影响环境的动态变化规律,因此当我们采用off-policy算法时(所学习的策略与正在执行的策略不一致),我们可以将trajectory里的目标更改为任意其他目标。
对于如何选取用于replay的目标,论文中提出了三种方案:
- final:选取每个episode所达到的最后一个状态 s_T 所对应的目标 m(s_T) 作为回放目标。
- future:从当前 transition 之后发生的transitions中选取 k 个状态所对应实现的目标作为回放目标。
- episode:从当前episode中随机选取 k 个状态所对应的目标作为回放目标。
- random:从当前整个训练过程所遇到过的状态中选取 k 个状态所对应的目标作为回放目标。
经验回放池中同时包含原本目标所对应的transition以及重新设定的目标所对应的transition,算法流程如下:

HER可以看做是一种 implicit curriculum,因为用来replay的目标会从较为容易的随机策略就能实现的目标逐渐转变为较难的目标。
仿真实验
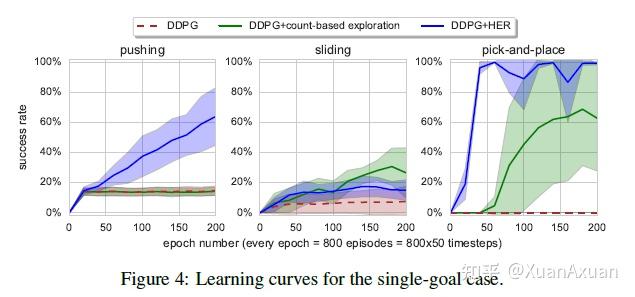
- 结合了HER的算法能够处理原本无法处理的稀疏奖励问题。
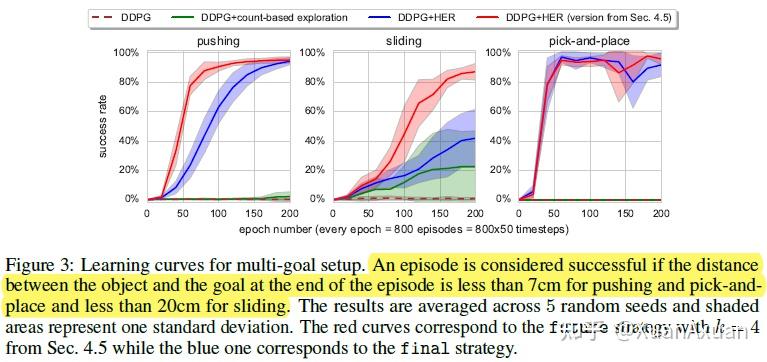
- 当训练中包含多个目标时,HER学习得更快,因此论文建议即使实际上只有1个目标,也最好用多个目标进行训练。
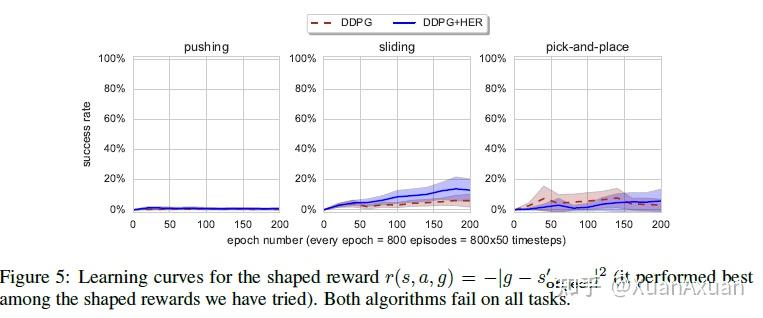
- 本文尝试了一种reshape reward,结果在该reward下,结合了HER与没结合HER的算法都没有办法解决问题,这可能是因为(1)所设计的奖励与实际的成功条件差别很大;(2)Shaped reward会惩罚不合适的行为,阻碍了智能体的探索。然而设计合适的奖励通常是很困难的,这就体现了HER的重要性。
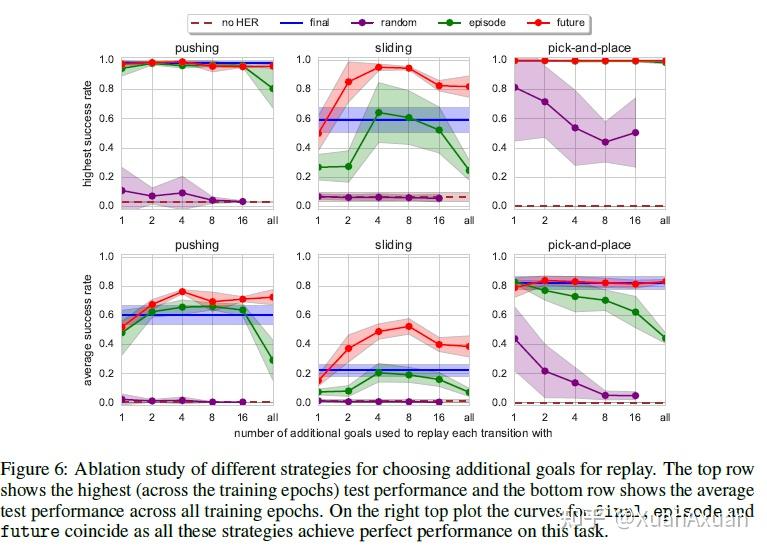
- 在所有指定目标的方法中,future 的效果是最好的。
个人思考
这篇论文针对奖励极稀疏的二元目标实现问题给出了一个看似十分简单但特别有效的方法,虽然全文并没有特别高深的理论推导,但是作者对于问题背景的思考以及算法的提出都很清楚地体现在了论文中,总结来说,我个人认为这篇论文非常值得一读。但是HER是否只能用在这种简单奖励中呢?如果是shaped reward的话,一定会像文中所展示的那样差吗?这些可能都需要用实验来验证。
参考文献
[1] M. Andrychowicz et al., ‘Hindsight Experience Replay’, arXiv:1707.01495 [cs], Feb. 2018, Accessed: Apr. 16, 2022. [Online]. Available: http://arxiv.org/abs/1707.01495 |
|



 发表于 2023-1-9 08:25:48
发表于 2023-1-9 08:25:48