CPU 并非 90% 的时间都在忙着,很大一部分时间在等待,或者说“停顿(Stalled)”了。这种情况表示处理器流水线停顿,一般由资源竞争、数据依赖等原因造成。多数情况下表现为等待访存操作,其中又以读操作为主。在停顿周期内,不能执行指令,这意味着你的程序不往前走。
值得注意的是,图中 “Stalled” 状态所占的比例是作者依据生产环境中的典型场景计算而来,具有普遍现实意义。因此,大多时候 CPU 处于停顿状态,而你却不知道,因为 CPU 利用率这个指标没有告诉你真相。通过进一步分析 CPU 停顿的原因,可以指导代码优化,提高执行效率,这是我们深入理解CPU微架构的动力之一。
2. CPU 利用率的真实含义是什么?
我们通常所说的CPU利用率是指 “non-idle time”:即CPU不执行 idle thread 的时间。操作系统内核会在上下文切换时记录CPU的运行时间。
假设一个 non-idle thread 开始运行,100ms 后结束,内核会认为这段时间内 CPU 利用率为 100%。这种度量方式源于分时复用系统。早在阿波罗登月舱的导航计算机中,idle thread 当时被叫做 “DUMMY JOB”,工程师通过比对运行 “DUMMY JOB” 和 “实际任务” 的时间来衡量导航系统的利用率。
那么这个所谓“利用率”的问题在哪儿呢?
当今时代,CPU 执行速度远远大于内存访问速度,等待访存的时间成为占用 CPU 时间的主要部分。当你在 top 中看到很高的 “%CPU”,你可能认为处理器是瓶颈,但实际上却是内存。
在过去很长一段时间内,CPU 频率增长的速度大于 DRAM 访存延时降低的速度(CPU DRAM gap),直到2005年前后,处理器厂商们才开始放弃“频率路线”,转向多核、超线程技术,再加上多处理器架构,这些都导致访存需求急剧上升。尽管厂商通过增大 cache 容量、优化 cache 策略、提升总线带宽来试图缓解访存瓶颈,但我们的程序仍深受 CPU stall 困扰。
3. 如何真正辨别 CPU 在做些什么?
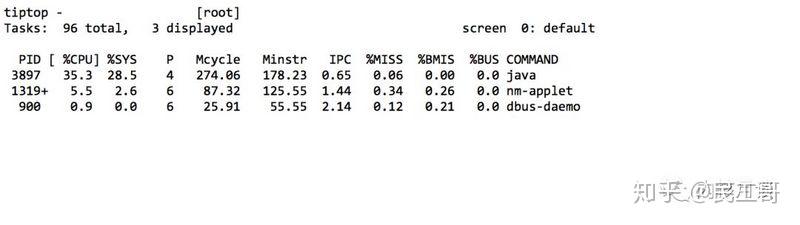
在 PMC(Performance Monitoring Counters) 的帮助下,我们能看到更多的 CPU 运行状态信息。下图中,perf 采集了10秒内全部 CPU 的运行状态。
总结下作者的回答是:这里讨论的并不是 iowait (那是磁盘IO),而且如果你已经确认是访存密集型,是有些处理办法(参考上面)。
那么 CPU 利用率指标是确确实实错误的,还是只是容易误导?如作者前面所说,他认为许多人把高 CPU 利用率理解为瓶颈在 CPU 上,这一行为才是错误的;
其实单看 CPU 利用率并不清楚瓶颈在何处,很多时候瓶颈是在外部。这个指标技术上看是否正确?如果 CPU stall 的周期并不能被其他地方使用,它们是不是也就因此是“忙于等待“(听起来有点矛盾)?在有些情况,确实如此,你可以说 CPU 利用率作为操作系统级别的指标技术上看是对的,但是容易产生误导。
从另一个角度来说,有超线程的情况下,那些 stalled 的周期是可以被其他线程使用的,这时 “%CPU” 可能会将可用的周期统计为正在使用,这种情况是错误的。这篇文章作者想关注的是解释清楚这个问题,并给出解决方法建议,但没错,CPU 利用率这个指标本身也是存在一些问题的。
当你可能会说利用率作为一个指标已经不对,Andrian Cockcroft之前讨论已经指出过 (http://www.hpts.ws/papers/200..._HPTS-Useless.pdf )。
8. 结论



 发表于 2023-3-26 18:27:26
发表于 2023-3-26 18:27:26