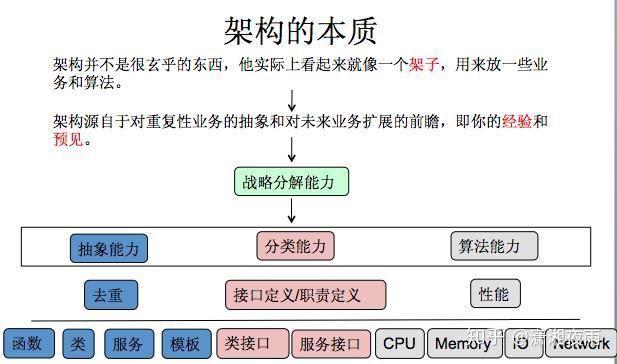
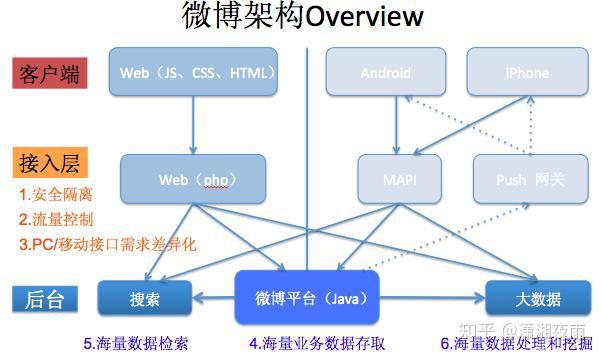
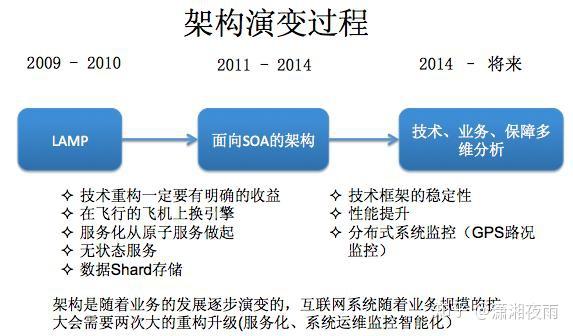
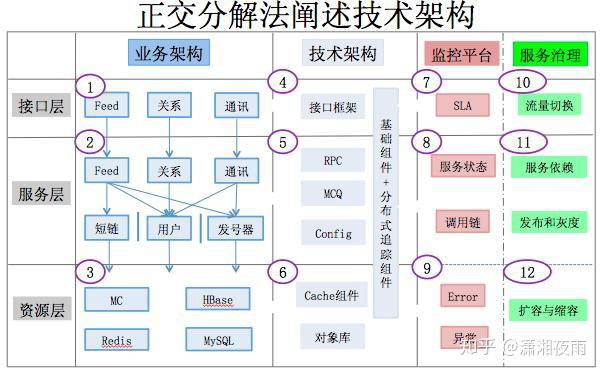
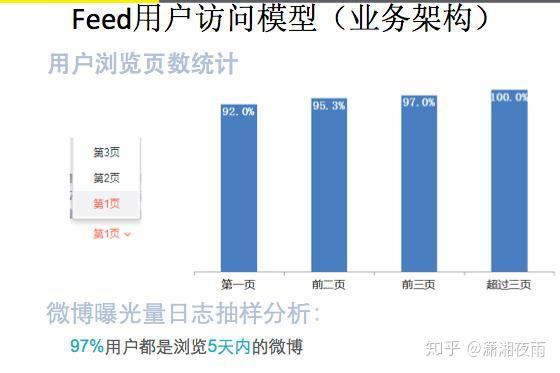
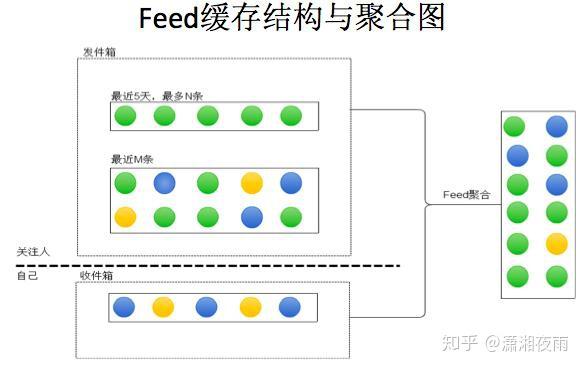
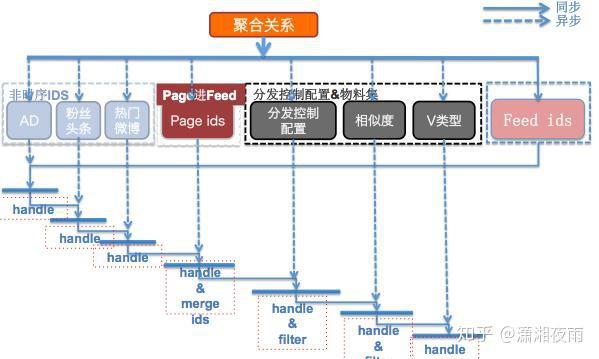
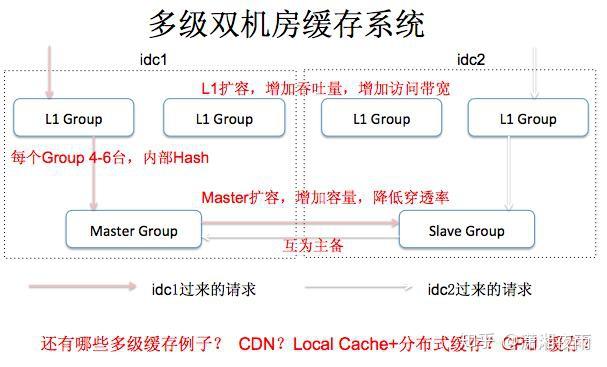
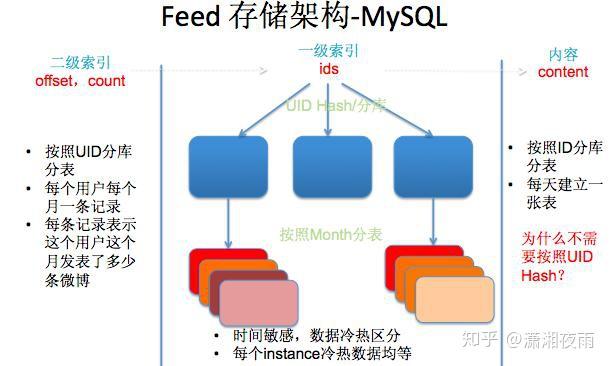
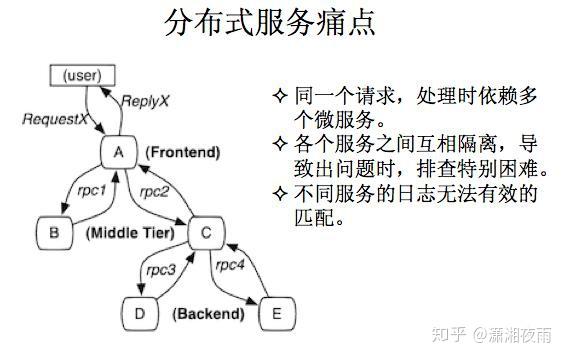
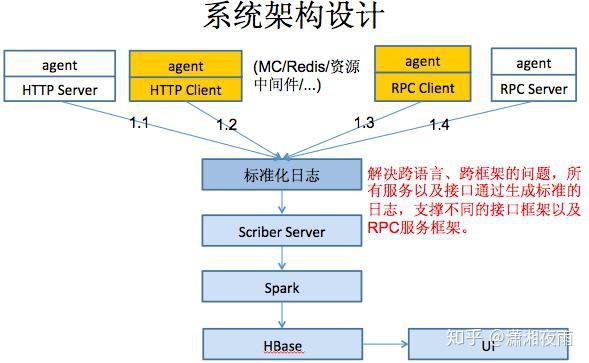
我们通过通过数据看一下它的挑战,PV是在10亿级别,QPS在百万,数据量在千亿级别。我们可用性,就是SLA要求4个9,接口响应最多不能超过150毫秒,线上所有的故障必须得在5分钟内解决完。如果说5分钟没处理呢?那会影响你年终的绩效考核。2015年微博DAU已经过亿。我们系统有上百个微服务,每周会有两次的常规上线和不限次数的紧急上线。我们的挑战都一样,就是数据量,bigger and bigger,用户体验是faster and faster,业务是more and more。互联网业务更多是产品体验驱动, 技术在产品体验上最有效的贡献 ,就是你的性能越来越好 。 每次降低加载一个页面的时间,都可以间接的降低这个页面上用户的流失率。



 发表于 2022-12-1 16:09:23
发表于 2022-12-1 16:09:23