|
|
关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
本文转自:深度学习这件小事
背景
PyTorch的动态图框架主要是由torch/csrc/autograd下的代码实现的。这个目录下定义了3个主要的基类:Variable、Function、Engine,这三个基类及其继承体系共同构成了PyTorch动态图的根基。
为什么叫作动态图呢?图容易理解,Function是nodes/vertices,(Function, input_nr)是edges。那么动态体现在什么地方呢?每一次前向时构建graph,反向时销毁。本文就以torch/csrc/autograd/下的代码为基础,深入讲解PyTorch的动态图系统——这也可能是互联网上关于PyTorch动态图最详尽的文章了。
在专栏文章《PyTorch的初始化》(https://zhuanlan.zhihu.com/p/57571317)中,gemfield描述了PyTorch的初始化流程,在文末提到了THPAutograd_initFunctions()调用:“最后的THPAutograd_initFunctions()则是初始化了torch的自动微分系统,这是PyTorch动态图框架的基础”。而本文将以THPAutograd_initFunctions开始,带你走入到PyTorch的动态图世界中。首先为上篇,主要介绍Function、Variable、Engine的类的继承体系。
autograd初始化
THPAutograd_initFunctions这个函数实现如下:
void THPAutograd_initFunctions(){ THPObjectPtr module(PyModule_New("torch._C._functions")); ...... generated::initialize_autogenerated_functions(); auto c_module = THPObjectPtr(PyImport_ImportModule("torch._C"));}
用来初始化cpp_function_types表,这个表维护了从cpp类型的函数到python类型的映射:
static std::unordered_map<std::type_index, THPObjectPtr> cpp_function_types
这个表里存放的都是和autograd相关的函数的映射关系,起什么作用呢?比如我在python中print一个Variable的grad_fn:
>>> gemfield = torch.empty([2,2],requires_grad=True)>>> syszux = gemfield * gemfield>>> syszux.grad_fn<ThMulBackward object at 0x7f111621c350>
grad_fn是一个Function的实例,我们在C++中定义了那么多反向函数(参考下文),但是怎么在python中访问呢?就靠上面这个表的映射。实际上,cpp_function_types这个映射表就是为了在python中打印grad_fn服务的。
Variable
参考:https://zhuanlan.zhihu.com/p/64135058
以下面的代码片段作为例子:
gemfield = torch.ones(2, 2, requires_grad=True)syszux = gemfield + 2civilnet = syszux * syszux * 3gemfieldout = civilnet.mean()gemfieldout.backward()
需要指出的是,动态图是在前向的时候建立起来的。gemfieldout作为前向的最终输出,在反向传播的时候,却是计算的最初输入—在动态图中,我们称之为root。在下文介绍Engine的时候,你就会看到,我们会使用gemfieldout这个root来构建GraphRoot实例,以此作为Graph的输入。
Function
在开始介绍Function之前,还是以上面的代码为例,在一次前向的过程中,我们会创建出如下的Variable和Function实例:
#Variable实例gemfield --> grad_fn_ (Function实例)= None --> grad_accumulator_ (Function实例)= AccumulateGrad实例0x55ca7f304500 --> output_nr_ = 0#Function实例, 0x55ca7f872e90AddBackward0实例 --> sequence_nr_ (uint64_t) = 0 --> next_edges_ (edge_list) --> std::vector<Edge> = [(AccumulateGrad实例, 0),(0, 0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])] --> alpha (Scalar) = 1 --> apply() --> 使用 AddBackward0 的apply#Variable实例syszux --> grad_fn_ (Function实例)= AddBackward0实例0x55ca7f872e90 --> output_nr_ = 0#Function实例, 0x55ca7ebba2a0MulBackward0 --> sequence_nr_ (uint64_t) = 1 --> next_edges_ (edge_list) = [(AddBackward0实例0x55ca7f872e90,0),(AddBackward0实例0x55ca7f872e90,0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])] --> alpha (Scalar) = 1 --> apply() --> 使用 MulBackward0 的apply# #Variable实例,syszux * syszux得到的tmptmp --> grad_fn_ (Function实例)= MulBackward0实例0x55ca7ebba2a0 --> output_nr_ = 0#Function实例,0x55ca7fada2f0MulBackward0 --> sequence_nr_ (uint64_t) = 2 (每个线程内自增) --> next_edges_ (edge_list) = [(MulBackward0实例0x55ca7ebba2a0,0),(0,0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2],cpu])] --> self_ (SavedVariable) = tmp的浅拷贝 --> other_ (SavedVariable) = 3的浅拷贝 --> apply() --> 使用 MulBackward0 的apply#Variable实例civilnet --> grad_fn_ (Function实例)= MulBackward0实例0x55ca7fada2f0 -#Function实例,0x55ca7eb358b0MeanBackward0 --> sequence_nr_ (uint64_t) = 3 (每个线程内自增) --> next_edges_ (edge_list) = [(MulBackward0实例0x55ca7fada2f0,0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType|[]|cpu])] --> self_sizes (std::vector<int64_t>) = (2, 2) --> self_numel = 4 --> apply() --> 使用 MulBackward0 的apply#Variable实例gemfieldout --> grad_fn_ (Function实例)= MeanBackward0实例0x55ca7eb358b0 --> output_nr_ = 0这些用于反向计算的Function实例之间通过next_edges_连接在一起,因为这些Function的实际运行都是在反向期间,因此,输出输出关系正好和前向期间是反过来的。它们通过next_edges_连接在一起。用一个图来概括,就是下面这样:
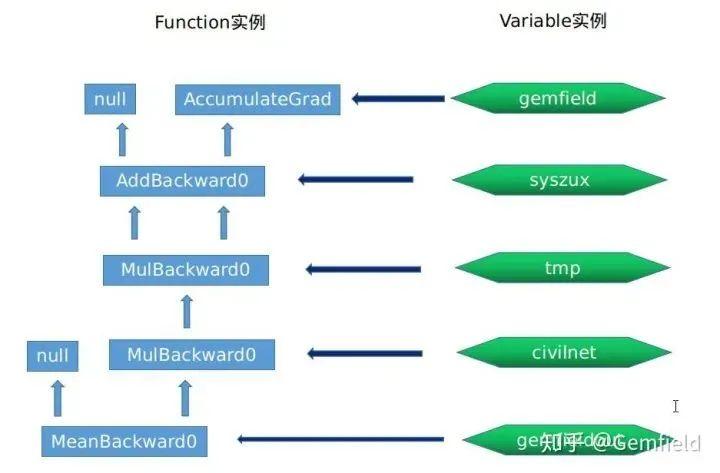
这就引入一个新的话题——Function类是如何抽象出来的。
#Function基类定义
Function的数据成员如下所示:
using edge_list = std::vector<Edge>;using variable_list = std::vector<Variable>;struct TORCH_API Function {... virtual variable_list apply(variable_list&& inputs) = 0;... const uint64_t sequence_nr_; edge_list next_edges_; PyObject* pyobj_ = nullptr; // weak reference std::unique_ptr<AnomalyMetadata> anomaly_metadata_ = nullptr; std::vector<std::unique_ptr<FunctionPreHook>> pre_hooks_; std::vector<std::unique_ptr<FunctionPostHook>> post_hooks_; at::SmallVector<InputMetadata, 2> input_metadata_;};
#Function call
Function类是抽象出来的基类,代表一个op(operation),每个op接收的参数是0个、1个或多个Variable实例(使用std::vector封装),并与此同时输出0个、1个或多个Variable实例。PyTorch中所有用于反向传播计算的函数都继承自Function类,并重写了Function类中的apply纯虚函数。因为Function类中实现了call函数:
variable_list operator()(variable_list&& inputs) { return apply(std::move(inputs));}所以依靠C++的多态,对op的call将转化为自身(子类)的apply调用。Function类中最重要的方法是call函数,call会调用apply,call函数接收vector封装的多个Variable实例,并输出vector封装的多个Variable实例。输入参数的vector长度可以由num_inputs()调用获得,对应的,输出的vector长度则由num_outputs()获得。
#Function的输入
Function成员input_metadata_代表input data的meta信息,界定了一个Function的输入:
struct InputMetadata {... const at::Type* type_ = nullptr; at::DimVector shape_; at::Device device_ = at::kCPU;};
#Autograd graph的edge和vertices
如果将PyTorch的autograd系统看作是一个图(graph)的话,那么每个Function实例就是graph中的节点(nodes/vertices),各个Function实例之间则是通过Edge连接的。Edge是个结构体,通过 (Function, input_nr) 的配对来代表graph中的edge:
struct Edge {... std::shared_ptr<Function> function; uint32_t input_nr;};
Function的成员next_edges_正是一组这样的Edge实例,代表此function实例的返回值要输出到的(另外)function,也即next_edges_是function和function之间的纽带。
Function的输入输出都是Variable实例,因此,当一个graph被执行的时候,Variable实例就在这些edges之间来传输流动。当两个或者多个Edge指向同一个Function的时候(这个节点的入度大于1),这些edges的输出将会隐含的相加起来再送给指向的目标Function。
Function和Function之间通过next_edge接口连接在一起,你可以使用add_next_edge()来向Function添加一个edge, 通过next_edge(index)获取对应的edge,通过next_edges()方法获得迭代edge的迭代器。每一个Function都有一个sequence number,随着Function实例的不断构建而单调增长。你可以通过sequence_nr()方法来或者一个Function的sequence number。
Function继承体系
基类Function直接派生出TraceableFunction和以下这些Function:
CopySlices : public Function DelayedError : public Function Error : public Function Gather : public Function GraphRoot : public Function Scatter : public FunctionAccumulateGrad : public Function AliasBackward : public Function AsStridedBackward : public Function CopyBackwards : public Function DiagonalBackward : public Function ExpandBackward : public Function IndicesBackward0 : public Function IndicesBackward1 : public Function PermuteBackward : public Function SelectBackward : public Function SliceBackward : public Function SqueezeBackward0 : public Function SqueezeBackward1 : public Function TBackward : public Function TransposeBackward0 : public Function UnbindBackward : public Function UnfoldBackward : public Function UnsqueezeBackward0 : public Function ValuesBackward0 : public Function ValuesBackward1 : public Function ViewBackward : public FunctionPyFunction : public Function
这其中,从基类Function派生出来的AccumulateGrad、TraceableFunction、GraphRoot是比较关键的类。
#派生类AccumulateGrad
先说说AccumulateGrad,AccumulateGrad正是Variable的grad_accumulator_成员的类型:
struct AccumulateGrad : public Function { explicit AccumulateGrad(Variable variable_); variable_list apply(variable_list&& grads) override; Variable variable;};
可见一个AccumulateGrad实例必须用一个Variable构建,apply调用接收一个list的Variable的实例——这都是和Variable的grad_accumulator_相关的。
#派生类GraphRoot
对于GraphRoot,前向时候的最终输出——在反向的时候作为最初输入——是由GraphRoot封装的:
struct GraphRoot : public Function { GraphRoot(edge_list functions, variable_list inputs) : Function(std::move(functions)), outputs(std::move(inputs)) {} variable_list apply(variable_list&& inputs) override { return outputs; } variable_list outputs;};
GraphRoot——正如Function的灵魂在apply一样——其apply函数仅仅返回它的输入!
#派生类TraceableFunction
再说说TraceableFunction:
struct TraceableFunction : public Function { using Function::Function; bool is_traceable() final { return true; }};TraceableFunction会进一步派生出372个子类(2019年4月),这些子类的名字都含有一个共同的部分:Backward。这说明什么呢?这些函数将只会用在反向传播中:
AbsBackward : public TraceableFunction AcosBackward : public TraceableFunction AdaptiveAvgPool2DBackwardBackward : public TraceableFunction AdaptiveAvgPool2DBackward : public TraceableFunction AdaptiveAvgPool3DBackwardBackward : public TraceableFunction AdaptiveAvgPool3DBackward : public TraceableFunction AdaptiveMaxPool2DBackwardBackward : public TraceableFunction AdaptiveMaxPool2DBackward : public TraceableFunction AdaptiveMaxPool3DBackwardBackward : public TraceableFunction AdaptiveMaxPool3DBackward : public TraceableFunction AddBackward0 : public TraceableFunction AddBackward1 : public TraceableFunction AddbmmBackward : public TraceableFunction AddcdivBackward : public TraceableFunction AddcmulBackward : public TraceableFunction AddmmBackward : public TraceableFunction AddmvBackward : public TraceableFunction AddrBackward : public TraceableFunction ......SoftmaxBackwardDataBackward : public TraceableFunction SoftmaxBackward : public TraceableFunction ......UpsampleBicubic2DBackwardBackward : public TraceableFunction UpsampleBicubic2DBackward : public TraceableFunction UpsampleBilinear2DBackwardBackward : public TraceableFunction UpsampleBilinear2DBackward : public TraceableFunction UpsampleLinear1DBackwardBackward : public TraceableFunction UpsampleLinear1DBackward : public TraceableFunction UpsampleNearest1DBackwardBackward : public TraceableFunction UpsampleNearest1DBackward : public TraceableFunction UpsampleNearest2DBackwardBackward : public TraceableFunction UpsampleNearest2DBackward : public TraceableFunction UpsampleNearest3DBackwardBackward : public TraceableFunction UpsampleNearest3DBackward : public TraceableFunction UpsampleTrilinear3DBackwardBackward : public TraceableFunction UpsampleTrilinear3DBackward : public TraceableFunction ......
这300多个Backward function都重写了apply函数,来实现自己的反向求导算法,比如加法的反向求导函数AddBackward0:
struct AddBackward0 : public TraceableFunction { using TraceableFunction::TraceableFunction; variable_list apply(variable_list&& grads) override; Scalar alpha;};
这些apply函数是Function的灵魂,是反向传播计算时候的核心执行逻辑。
Engine
Engine类实现了从输出的variable(以及它的gradients)到root variables(用户创建的并且requires_grad=True)之间的反向传播。
gemfield = torch.ones(2, 2, requires_grad=True)syszux = gemfield + 2civilnet = syszux * syszux * 3gemfieldout = civilnet.mean()gemfieldout.backward()
还是以上面这个代码片段为例,Engine实现了从gemfieldout到gemfield的反向传播:
1,如何根据gemfieldout构建GraphRoot;
2,如何根据这些Function实例及它们上的metadata构建graph;
3,如何实现Queue来多线程完成反向计算的工作。
#Engine类定义
Engine类的定义如下:
struct Engine { using ready_queue_type = std::deque<std::pair<std::shared_ptr<Function>, InputBuffer>>; using dependencies_type = std::unordered_map<Function*, int>; virtual variable_list execute(const edge_list& roots,const variable_list& inputs,...const edge_list& outputs = {}); void queue_callback(std::function<void()> callback);protected: void compute_dependencies(Function* root, GraphTask& task); void evaluate_function(FunctionTask& task); void start_threads(); virtual void thread_init(int device); virtual void thread_main(GraphTask *graph_task); std::vector<std::shared_ptr<ReadyQueue>> ready_queues;};
核心就是execute函数,它接收一组Edge——(Function, input number) pairs ——来作为函数的输入,然后通过next_edge不断的找到指向的下一个Edge,最终完成整个Graph的计算。
#派生类PythonEngine
然而我们实际使用的是Engine类的派生类:PythonEngine。PythonEngine子类重写了父类的execute,只不过仅仅提供了把C++异常翻译为Python异常的功能,核心工作还是由Engine基类来完成:
struct PythonEngine : public Engine整个PyTorch程序全局只维护一个Engine实例,也就是PythonEngine实例。
BP调用栈
既然Engine是用来计算网络反向传播的,我们不妨看下这个调用栈是怎么到达Engine类的。如果我们对gemfieldout进行backward计算,则调用栈如下所示:
#torch/tensor.py,self is gemfieldoutdef backward(self, gradient=None, retain_graph=None, create_graph=False)|V#torch.autograd.backward(self, gradient, retain_graph, create_graph)#torch/autograd/__init__.pydef backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)|VVariable._execution_engine.run_backward(tensors, grad_tensors, retain_graph, create_graph,allow_unreachable=True)#转化为Variable._execution_engine.run_backward((gemfieldout,), (tensor(1.),), False, False,True)|V#torch/csrc/autograd/python_engine.cppPyObject *THPEngine_run_backward(THPEngine *self, PyObject *args, PyObject *kwargs)|V#torch/csrc/autograd/python_engine.cppvariable_list PythonEngine::execute(const edge_list& roots, const variable_list& inputs, bool keep_graph, bool create_graph, const edge_list& outputs)|V#torch/csrc/autograd/engine.cpp总结
在下段文章中,Gemfield将主要介绍Engine这个类是如何在gemfieldout.backward()中运行PyTorch动态图的。
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索 |
|



 发表于 2023-1-1 10:30:15
发表于 2023-1-1 10:30:15