|
|
End-to-End Object Detection with Transformers
该篇文章由Facebook AI发表,把《Attention is All You Need》的Transformer应用到目标检测出,去除了Anchor机制、NMS后处理,首次提出了目标检测一个新的Baseline。阅读此文章需要Transformer知识,以下这篇文章介绍的非常详细,非常推荐看。
Input
此处作者定义了NestedTensor类,假设输入batch2的图片:
im0 = torch.rand(3,200,200)
im1 = torch.rand(3,200,250)
x = nested_tensor_from_tensor_list([im0, im1])NestedTensor 指的是把 {tensor, mask} 打包在一起,tensor就是图片的值,那么mask是什么呢? 当一个batch中的图片大小不一样的时候,我们要把它们处理的整齐,简单说就是把图片都padding成最大的尺寸,padding的方式就是补零,那么batch中的每一张图都有一个mask矩阵,所以mask大小为(2, 200, 250), tensor大小为(2, 3, 200, 250)。
Backbone
Backbone采用ResNet,输出(2, 1024, 24, 32),其次输出mask(2, 24, 32),mask采用F.interpolate得到。
Positional Encoding
《Attention is All You Need》的Transformer中用到Positional Embedding。
Transformer摒弃了NLP中常用的RNN(由于不能并行计算),而采用其他机制把位置信息传入到Encoding部分。所以模型中,每个时刻输入的是Word Embedding + Position Embedding。该文用sin,cos构造每个位置的值,Detr基本与该方法一致。
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors #(2,1024, 24,32)
mask = tensor_list.mask #(2, 24,32)
assert mask is not None
not_mask = ~mask #就是有像素值得位置
y_embed = not_mask.cumsum(1, dtype=torch.float32) #沿y方向累加,(1,1,1)--(1,2,3)
# (1,1,1,...) #y_embed
# (2,2,2,...)
# (3,3,3,...)
# (...)
x_embed = not_mask.cumsum(2, dtype=torch.float32) #沿x方向累加,(1,1,1).T--(1,2,3).T
# (1,2,3,...) #x_embed
# (1,2,3,...)
# (1,2,3,...)
# (...)
if self.normalize: #进行归一化
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale #(2,24,32)
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale #(2,24,32)
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
# self.num_pos_feats=128,
# dim_t = [1,2,3,4,...,128]
# 以下按上述公式计算
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t #(2,24,32,128)
pos_y = y_embed[:, :, :, None] / dim_t #(2,24,32,128)
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos #(2,256, 24,32)位置编码(positional encoding),最直观方式是将第一个pixel赋予1,第二个pixel赋予2,以此类推,但当pixel序列足够大时,会造成位置嵌入(positional embedding)的值过大,所以采用正弦曲线把值控制在-1到1之间,但由于正弦曲线的周期性,可能会造成不同位置值相同的情况。
因此,作者将positional embedding 扩充为一个d维的向量,这个向量用来为每个pixel提供位置信息,再和该位置的pixel embedding相加,增强模型输入,至于引用d维正弦函数的作用大致是控制不同通道位置编码的波长,波长随d由小到大。以下是positional encoding过程的举例。
PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}})
PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}})

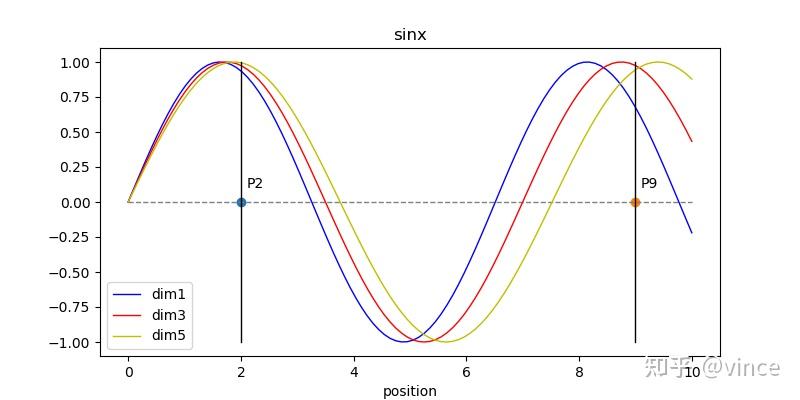
下图为不同维度对应的正弦曲线,可以看到随d越大,正弦曲线的波长越大,这样做的原因是,如果每个Position只对应一个正弦曲线,那么由于正弦曲线的周期性,P2,P9(不同的位置点)可能计算出相同值。而采用每个位置对应多个维度,即多个不同波长的正弦曲线,任何两位置由d维向量表示,就不会发生位置不同,值相同的情况。
另外positional embedding的周期有 2\pi 到10000 \ast2\pi 变化,而每个位置在embedding demension上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,最终使模型学到位置之间的依赖关系和自然语言的时序特征(Pixel的时序特征)。
论文中引入attention机制使用的模块是transformer,第一步先要将feature map投射变换成Q,K,V,Q可以理解为语义空间向量投射变维的输出,K可以理解为字典,V为字典对应的输出,通过Q与K点乘(典型的attention操作)得到V的加权系数,然后对V加权求和,最后经过一个前向网络输出类别和坐标预测,transformer丢失位置信息,所以又添加了一个位置编码(Position Enconding),所谓PE是根据目标的位置坐标,将位置坐标转换为固定维度的编码,转换方式是将位置坐标代入不同波长的三角函数里,三角函数天生具有描述相对位置的作用,而之所以要使用不同波长的三角函数进行计算而不是单波长,是为了描述相对位置同时保存绝对位置,因为波长过小,位置较远的像素将超出同一个周期导致绝对位置丢失,所以大家可以粗略的理解为,小波长精确描述距离较近的相对位置,大波长描述距离较远绝对位置。 Transformer
首先回顾一下《Attention is All You Need》中Self-Attention,Thinking Machines句子经过QKV自注意力机制过程如下。图像中可把Thinking、Machines认为两个相邻位置的像素。
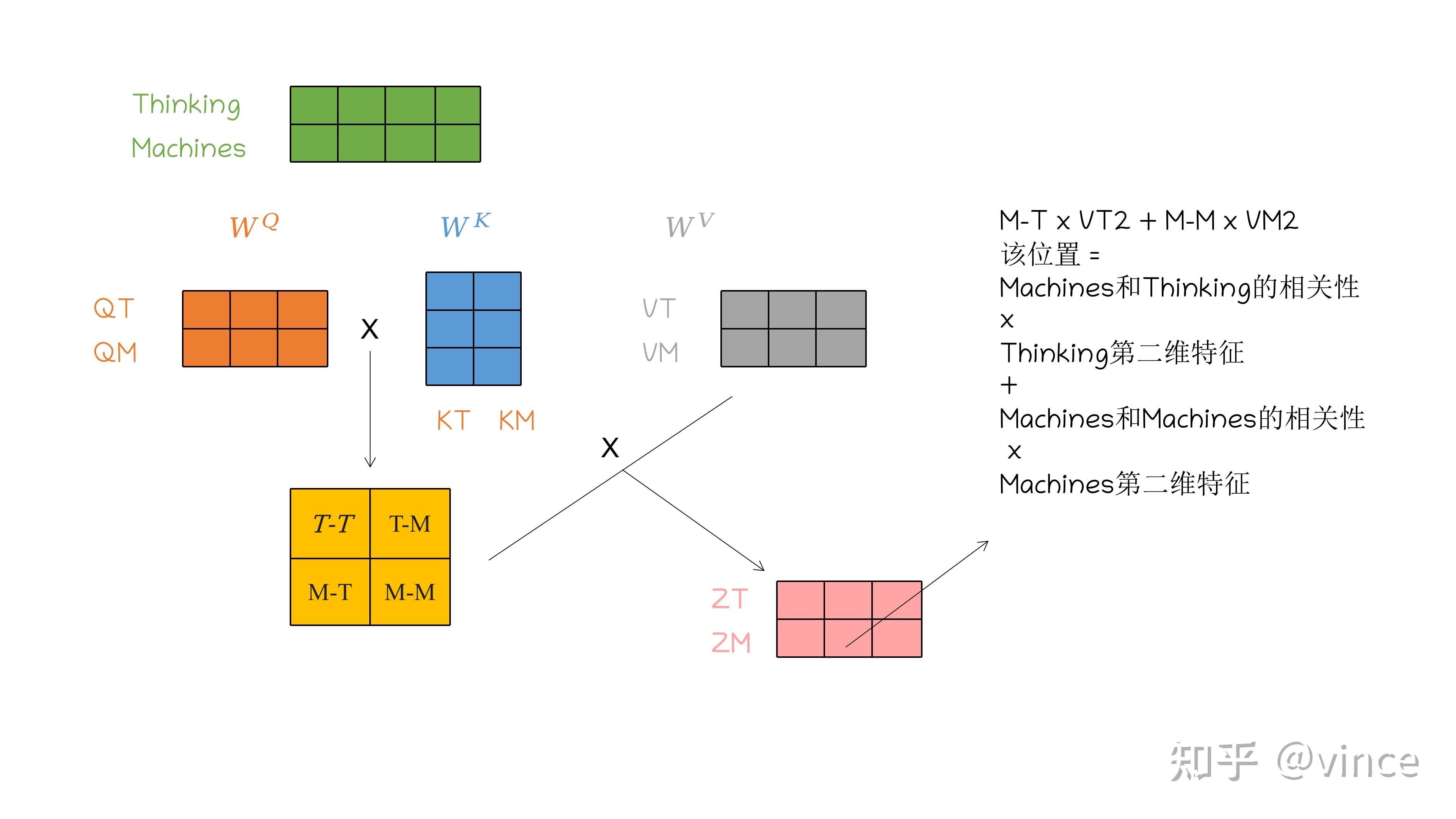
想具体了解这部分还需要阅读开头推荐的文章,下面从encoder,decoder两方面介绍。
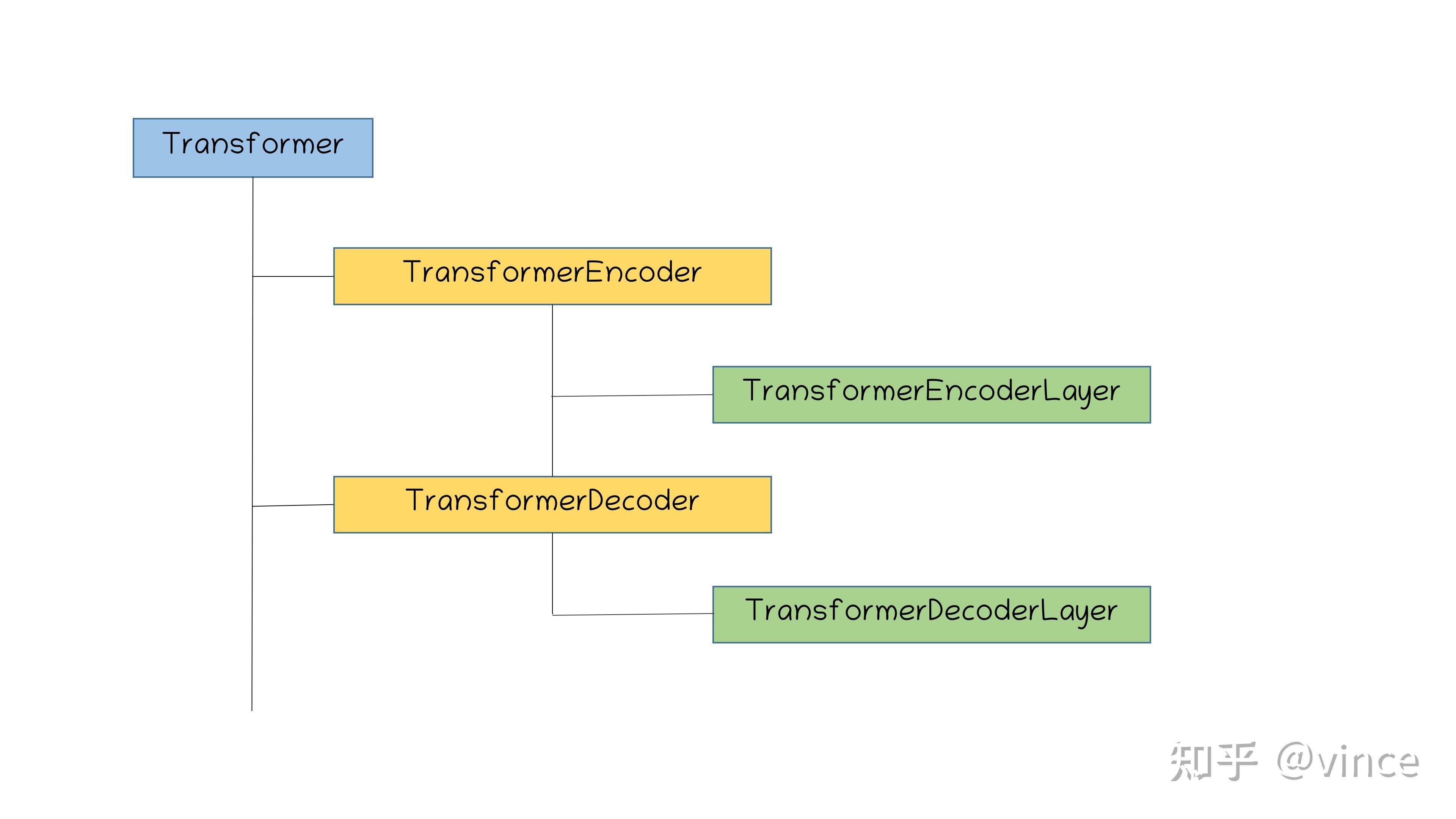
先看一下Transformer部分的代码结构
经过上面Positional Encoding后,我们已得到:
src(2, 256, 24, 32),mask(2, 24, 32),pos(1, 2, 256, 24, 32)。
hs = transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]hs是传入Transformer的输入,其中input_proj是一个卷积层,卷积核为1*1,就是压缩通道,将2048压缩到256,所以传入transformer的维度是压缩后的[2, 256, 24, 32]。self.query_embed.weight在decoder的时候用的到,后面再讲。
TransformerEncoder
接下来看一下论文代码中TransformerEncoder。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
# self.layers总共循环6层
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output上面代码encoder_layer就是TransformerEncoderLayer,接下来看TransformerEncoderLayer中forward部分。
# TransformerEncoderLayer
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# self.with_pos_embed: return tensor if pos is None else tensor + pos
q = k = self.with_pos_embed(src, pos)
# q(768,2,256) k(768,2,256) value(768,2,256)
# src_mask=None key_padding_mask(2,768)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
# src2(768,2,256)
# Residual Connection
src = src + self.dropout1(src2)
# Layer Normaliztion
src = self.norm1(src)
# 一层Relu,两层linear ffn
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# Residual Connection
src = src + self.dropout2(src2)
# Layer Normaliztion
src = self.norm2(src)
# src(768,2,256)
return src此时可以知道Encoder部分由6个TransformerEncodeLayer组成,每个TransformerEncodeLayer由1个self_attention,2个ffn,2个norm。最后经过Encoder输出memory的size依然为(768, 2, 256)。
TransformerDecoder
先解释上面的self.query_embed.weight。
# num_queries = 100 hidden_dim = 256
self.query_embed = nn.Embedding(num_queries, hidden_dim)意思就是初始化一个(100, 256)的框向量(box-embeding)。
再看一下decoder的输入
tgt = torch.zeros_like(query_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)tgt=(100,2,256),memorty=(768,2,256),mask还是上面的mask=(2,768),pos_embed还是上面的pos_embed=(768,2,256),query_embed就是self.query_embed.weight = (100,2,256)。
先看TransformerDecoder
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
# 总共6层,第一层的output值为0,第二层的output为上一层的输出,依次类推。
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate) # return (6,100,2,256)
return output.unsqueeze(0)上面代码layer就是TransformerDecoderLayer,接下来看TransformerDecoderLayer中forward部分。
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# tgt(100,2,256) + query_pos(100,2,256),
# 第一层的tgt=torch.zeros_like(query_embed)(query_pos=query_embed)
q = k = self.with_pos_embed(tgt, query_pos)
# q(100,2,256),k(100,2,256),value(100,2,256)
# tgt_mask(None),tge_key_padding_mask(None)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# tgt2(100,2,256)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# q和上面一样,来自self.attn的输出,k,v来自encoder的输出memory
# q(100,2,256) k(768,2,256) v(768,2,256)
# memory_mask(None) memory_key_padding_mask(2,768)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# tgt2(100,2,256)
# Residual Connection
tgt = tgt + self.dropout2(tgt2)
# Layer Norm
tgt = self.norm2(tgt)
# FFN
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
# Residual Connection
tgt = tgt + self.dropout3(tgt2)
# Layer Norm
tgt = self.norm3(tgt)
# tgt(100,2,256)
return tgt此次可以知道经过Decoder后输出为(100,2,256),其中100对应网络预测的框数。
最后看一下Transformer部分代码就很容易懂了。
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
# 最后输出(6,2,100,256)来自self.decoder
# (2,256,24,32) 来自self.encoder最终网络结构图如下:

Loss Cost
假设target:t1(dog),t2(cat),t3(pepole),... t8(car)
匹配部分,首先计算二分匹配图的cost-matrix,由3部分组成:
1、cost_class,100个预测框取对应target的类别分数。
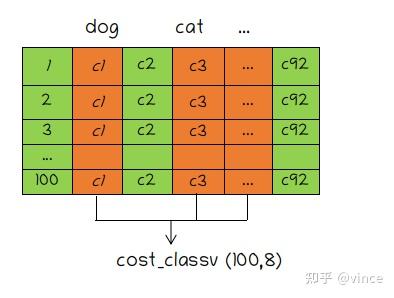
2、cost_bbox(100,8),100个预测框和8个目标框间的L1距离。
3、cost_giou(100,8),100个预测框和8个目标框间的giou值。
costmatrix = \lambda_{1}costclass+\lambda_{2}costbbox+\lambda_{3}costgiou
再通过linear_sum_assignment计算最优匹配:
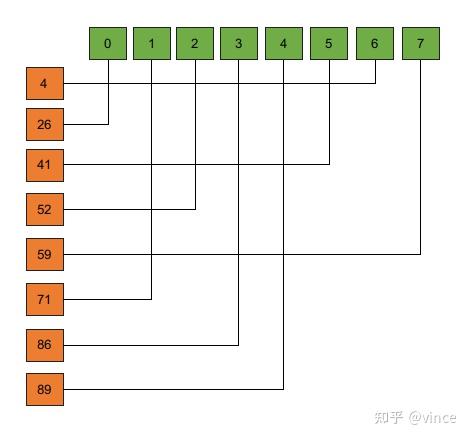
损失函数由三部分组成:
1、loss_labels
经过二分匹配,100个预测框对应的label为下图,然后计算100个预测框的CE。
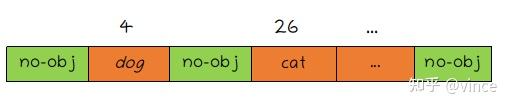
2、loss_cardinality
计算每次100个预测框算出来的类别中是物体的个数与target中物体数(8个)计算l1-loss,该部分不参与反向传播,例如一个预测出100个框中有99个物体,那么该部分损失为99-8=91。
3、loss_boxes
计算每次100个预测中匹配到有物体的框(4,26,...,89)与对应的目标框(8个)计算L1-loss+giouLoss。 |
|



 发表于 2023-1-9 12:46:55
发表于 2023-1-9 12:46:55