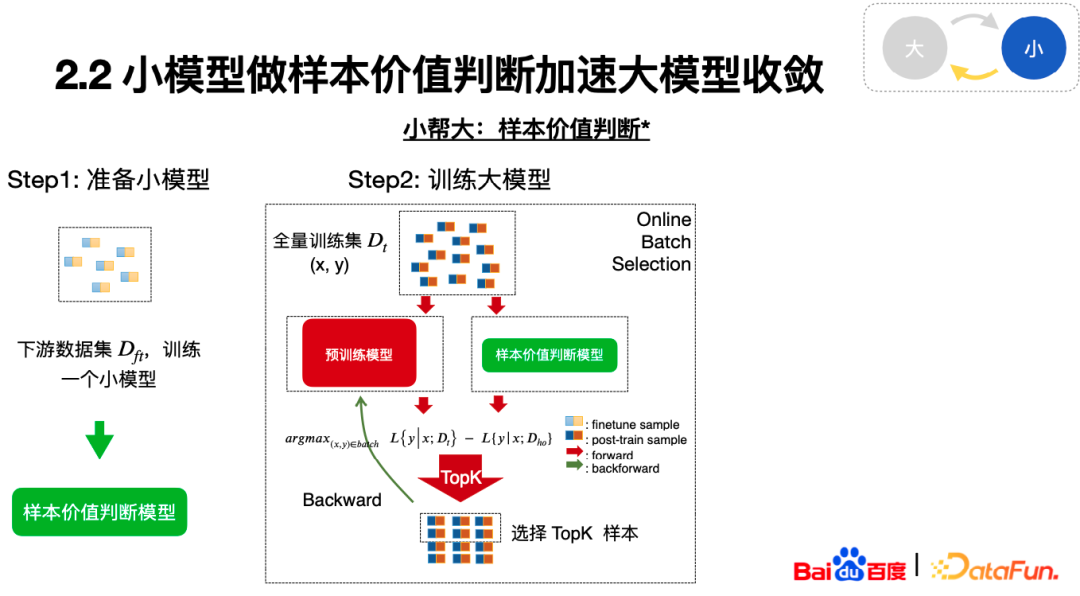
第二个点是利用小模型作样本价值判断。
背景是大模型训练过程耗时较久,我们考虑到在训练过程中每一条样本的价值是相同的吗?每一条样本都需要训练吗?学习过的样本还需要在学习吗?
因此我们引入了一种学术界的方法,可以利用小模型作为样本价值判断模型帮助大模型快速学习。首先先准备一个小模型,将小模型在下游数据集上进行 Fine Tune 得到样本价值判断模型。第二步将大模型在全量数据集上进行训练得到预训练模型,计算预训练模型和样本价值判断模型的 Loss 差值,定义这个 Loss 之差是样本的价值,然后按照这个价值进行排序选出 Top K 的样本进行梯度回传,通过这样的方式让更有价值的样本影响大模型的训练。
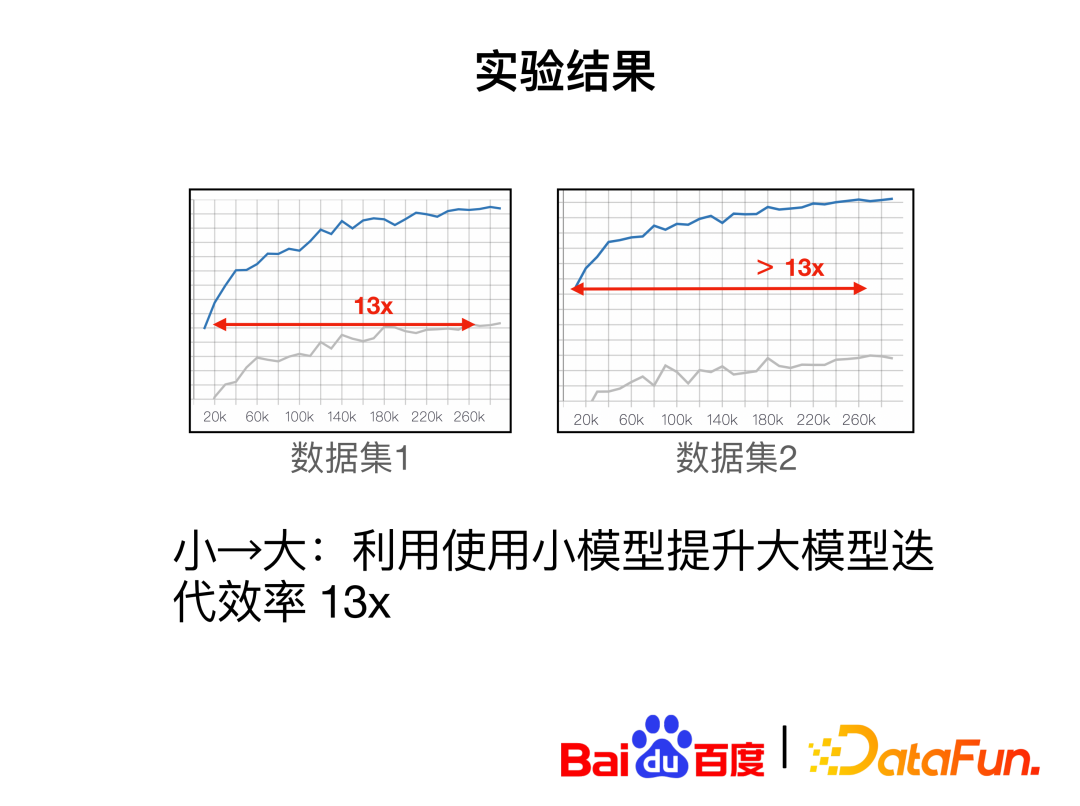
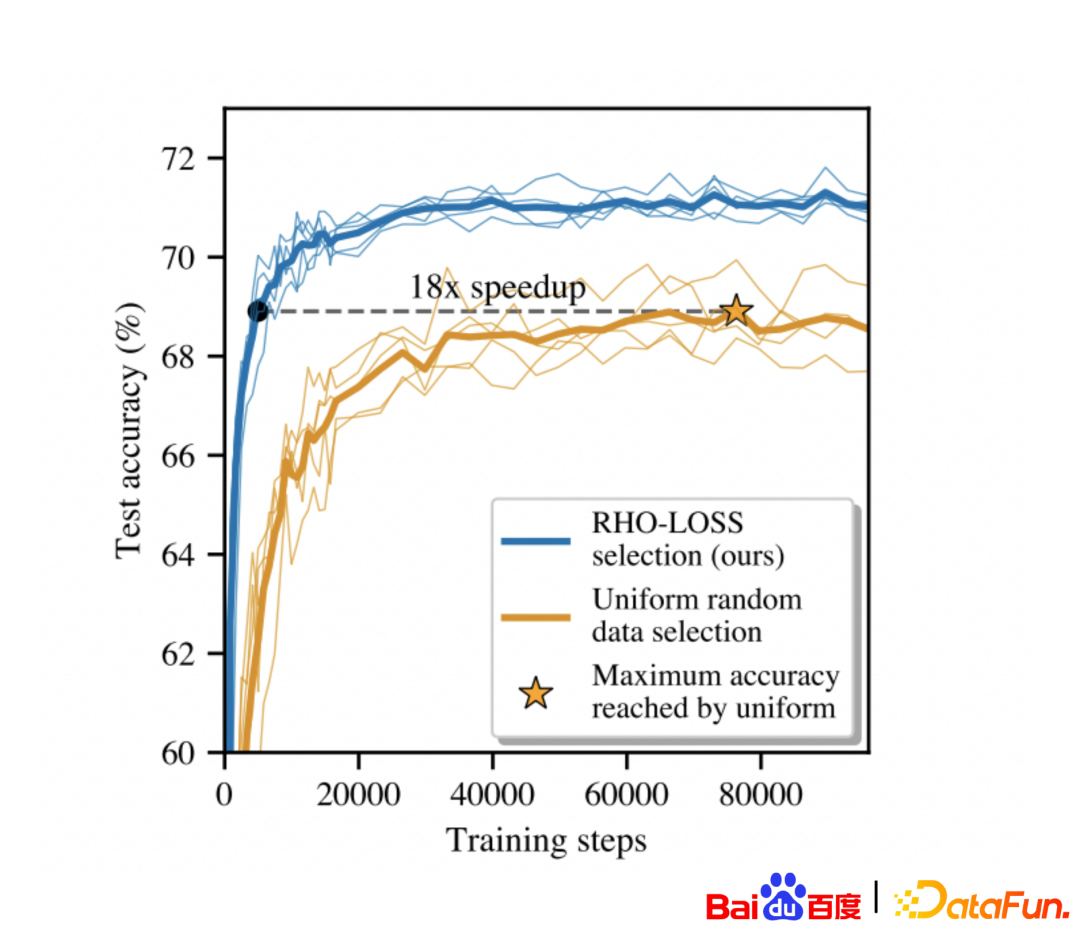
样本价值背后的逻辑是假设左边是大模型的 Loss,右边是小模型的 Loss,如果大模型的 Loss 大于小模型的 Loss,说明大模型还没有学会这条样本,小模型已经学会了,小模型可以反哺大模型;如果两个 Loss 都小说明它是一个非常简单的样本。大模型的 Loss 小,小模型的 Loss 大,说明这条样本是小模型的分布之外的样本,就没有必要继续学它。按照这样的推演逻辑,去把高价值的样本保留下进行学习,从相关的测试可以看出,黄线是加入了这个策略之后的效果,蓝线是加入策略之前的效果,我们可以看到在达到同样的指标的情况下,该方法需要的步数更短;纵向来看,最终的效果也有提升。



 发表于 2022-12-1 19:46:59
发表于 2022-12-1 19:46:59